 LinkedIn
LinkedIn  Contact Us
Contact Us HPC User Forum Highlights: The Future of Smarter MPI & Smarter Networks

A Hyperion Research study found over half of the High-Performance Computing (HPC) sites they surveyed have adopted the Message Passing Interface (MPI) as their parallel programming model, but they faced challenges with its use. Rockport and Hyperion recently convened a panel discussion “Smarter Networks, Smarter MPI: Improving MPI User Experience & Cluster Performance” to see how the situation could be improved. Here’s a recap of key ideas from the discussion, which was moderated by Mark Nossokoff of Hyperion Research, and featured Dr. John McCalpin, Dr. DK Panda, Dr. Ryan Grant and our own Matthew Williams as speakers.
The HPC Community Relies on MPI, But It’s Hard Work
MPI adoption is driven by the fact that the primary model of high-performance computing is based on performing parallelizing complex workloads over loosely coupled clusters of small nodes. This is because both processor frequencies and memory bandwidth per core have not significantly improved since the early 2000’s, cache sizes per core haven’t systematically increased and special features, such as wider SIMD arithmetic, have limited applicability and reduce average frequency when used. The only way to get more performance, therefore, is to parallelize over more hardware and MPI is the de-facto standard to program those HPC cluster systems.
While MPI is very familiar to the HPC community, it’s being mapped onto the systems that are increasingly complex, largely due to the number of interacting components involved and the imperfect sharing of information between all those components.
For example, the left-hand side of the diagram below shows a high-level stack of what’s actually happening in each node. An application performing a reduction makes calls to an MPI library and may go through a communication framework, select transports, goes through a driver complex, a host interface and then finally into the network.
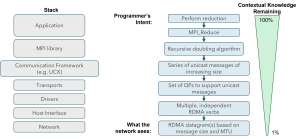
The blue boxes on the right illustrate what the program is trying to accomplish to perform the science, but every time you go through one of these layers, some amount of information is lost, so in the end, traditional networks don’t know what the program is trying to accomplish, it’s forced to work without any context and performance suffers as a result.
And, despite decades of development, most current InfiniBand and OmniPath networks are limited by static routing, making it effectively impossible to use all the available bandwidth at the same time. While advances in adaptive routing and the ability to use QoS to minimize contention between independent traffic will help, this problem will continue to get harder as systems become larger, more heterogeneous, and more heavily shared, and as organizations attempts to run larger and larger programs.
MPI is Responding and Getting Better All the Time
When the first MPI specification was published, it was roughly 240 pages long; it’s now up to 1139 pages. This speaks to both the increased complexity of the hardware and software in use, as well as the work done by specific MPI libraries.
MVAPICH, for example, has been working on many of the issues, there are hundreds of designs inside the MVAPICH2 library and has seen good results. The most notable amongst these aimed at better integration between MPI and the network include:
- Direct Connect (DC) protocol for scalable inter-node communication with reduced memory footprint (learn more)
- Scalable collective communication support with SHARP in-network computing (learn more)
- Hardware tag-matching support (learn more)
- Optimized derived datatype support (learn more)
- Non-blocking collective support with DPUs (learn more)
- QoS-aware designs (learn more)
Tighter Coupling Between MPI and the Network is Key
The topic of making both MPI and networks smarter boils down to providing more information and more context, both to the network and to the stack through the MPI library. On the network side, instead of using heuristics to figure out what kind of traffic is flowing through the network, MPI can provide explicit notifications so the network can treat traffic correctly from the first packet. The network will then know whether the traffic requires latency performance for small messages or bandwidth performance for large messages, if there is a lot of one-to-many large message traffic, and more, so the network can optimize its behavior for that traffic to provide better performance
The network can also provide information back to the stack, including static information such as the size of the cluster, how many nodes are involved, and the percentage of the network capacity needed. Depending on the size of the job relative to the cluster, better algorithms and transports can be used. Or the network can inform the MPI if some local or global congestion is present so it can employ optimized algorithms and transports to improve performance.
We don’t want programmers or applications to have to change – it’s too labor intensive. Programmers should be able to run that same code on a smarter network with smarter MPI and see overall better performance.
Rockport is Building a Smarter Network to Enable Smarter MPI
The Rockport Switchless Network has been designed from the ground-up to be more intelligent than traditional networking technology, making tighter integration with MPI possible. This includes features such as per-packet adaptive routing, which gives a Rockport-based network the flexibility in multi-job environments to optimize packet movement based on conditions in the network in real time. Another feature is advanced congestion control, which ensures latency-sensitive critical messages are immune to congestion. Rockport also provides rich tooling, powerful analytics and a lot of data store, so when jobs complete there’s a lot of information available to the system administrators and programmers to see exactly what the network was doing as the system completes workloads.
Rockport is also actively working with the HPC community to ensure MPI can take advantage of these advanced features and deliver that tighter integration between MPI and the network. In particular, we’re collaborating with the Ohio State University and their MVAPICH2 MPI library to get more intelligence into the system. Sign up to our mailing list to be the first to know about the results of that collaboration and to learn more about how a smarter Rockport Switchless Network can help you produce more results.
Watch the full recording of the event below.